Blog
在 Golang 中计算包含emoji等特殊字符的字符串中的字符数 | Go语言
问题
如何计算字符串中的(所见)字符数是一个常见的问题。
在 Golang 中,我们可以使用utf8.RuneCountInString()函数来计算字符串中的字符数。
中文这样的多字节字符也可以正确计算。
示例
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
str := "abc世界"
fmt.Println(utf8.RuneCountInString(str)) // 5
}但是如果字符串中包含 👉🏻 这样的 emoji 字符,那么有些情况下这个函数就无法正确计算了。
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
emojiWorld := "🌍"
fmt.Println(utf8.RuneCountInString(emojiWorld)) // 1 ✅ 没有问题
emojiHand := "👉"
fmt.Println(utf8.RuneCountInString(emojiHand)) // 1 ✅ 没有问题
emojiHandBlack := "👉🏿"
fmt.Println(utf8.RuneCountInString(emojiHandBlack)) // 2 ❌ 有问题 期望是 1。 同一种 emoji,但是不同的皮肤颜色的字符数不一样
emojiOne := "1️⃣"
fmt.Println(utf8.RuneCountInString(emojiOne)) // 3 ❌ 有问题 期望是 1。
}emoji 可以从这里emojipedia复制。
原因
这是因为有些 emoji 是多个 unicode 字符 (Code Points) 组合而成的,而 utf8.RuneCountInString() 函数只会计算 unicode 字符的数量。
| 术语 | 描述 |
|---|---|
| Bytes(字节) | 计算数据存储的最小单元,通常是 8 位二进制。 |
| Code Units(编码单元) | 在编码方案中,用于表示一个字符的固定大小的单元。在 UTF-8 中,一个 Code Unit 是 8 位,而在 UTF-16 中,是 16 位。 |
| Code Points(码点) | 在 Unicode 标准中,每个字符都被分配一个唯一的代码点,是一个用来标识字符的数字。例如,拉丁字母”A”的代码点是 U+0041。 |
| Grapheme Clusters(字符簇) | 表示语言中可感知的最小字符单元,通常是一个或多个 Code Points 组成的序列。例如,字母加重音符可能是一个 Grapheme Cluster。 |
比如 1️⃣ 这个 emoji,它是由 3 个 Code Points 组成的,分别是:
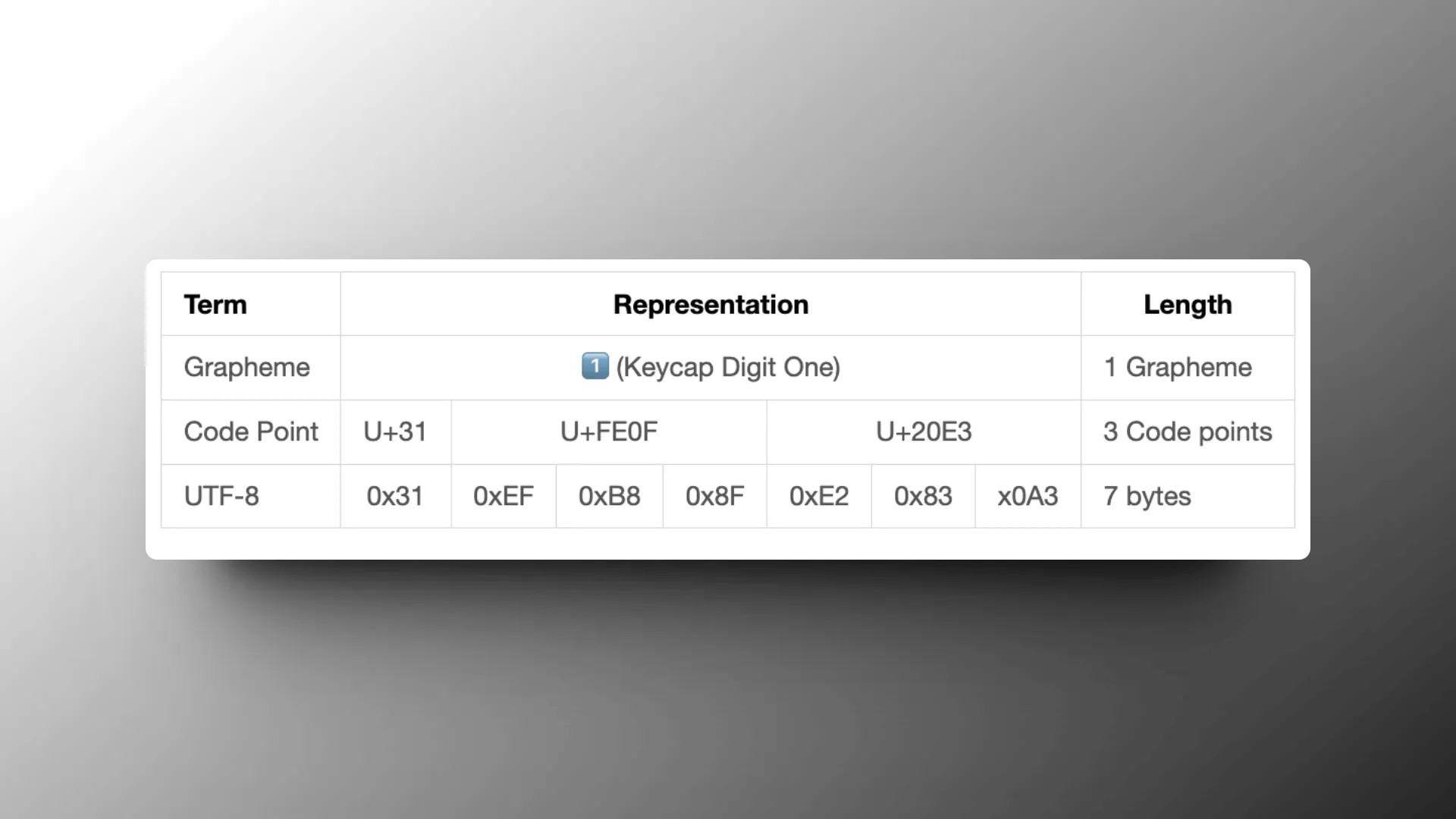
Rendered by Markdown Table
:::tip Emoji 的 Code Points 可以在这里emojipedia 查看。 :::
解决方案
所以我们需要计算的是 Grapheme Clusters(字符簇)的数量,而不是 Code Points 的数量。
使用第三方库 rivo/uniseg
package main
import (
"fmt"
"github.com/rivo/uniseg"
)
func main() {
emojiWorld := "🌍"
fmt.Println(uniseg.GraphemeClusterCount(emojiWorld)) // 1 ✅ 没有问题
emojiHand := "👉"
fmt.Println(uniseg.GraphemeClusterCount(emojiHand)) // 1 ✅ 没有问题
emojiHandBlack := "👉🏿"
fmt.Println(uniseg.GraphemeClusterCount(emojiHandBlack)) // 1 ✅ 没有问题
emojiOne := "1️⃣"
fmt.Println(uniseg.GraphemeClusterCount(emojiOne)) // 1 ✅ 没有问题
}补充
其实不只是 emoji,还有一些泰语,阿拉伯语的字符也是由多个 unicode 字符组成的。